Cache algorithms
In computing, cache algorithms (also frequently called replacement algorithms or replacement policies) are optimizing instructions – algorithms – that a computer program or a hardware-maintained structure can follow to manage a cache of information stored on the computer. When the cache is full, the algorithm must choose which items to discard to make room for the new ones.
The average memory reference time is[1]
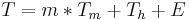
where
- T = average memory reference time
- m = miss ratio = 1 - (hit ratio)
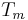 = time to make a main memory access when there is a miss (or, with multi-level cache, average memory reference time for the next-lower cache)
= time to make a main memory access when there is a miss (or, with multi-level cache, average memory reference time for the next-lower cache)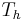 = the latency: the time to reference the cache when there is a hit
= the latency: the time to reference the cache when there is a hit- E = various secondary effects, such as queuing effects in multiprocessor systems
There are two primary figures of merit of a cache: The latency, and the hit rate. There are also a number of secondary factors affecting cache performance.[1]
The "hit ratio" of a cache describes how often a searched-for item is actually found in the cache. More efficient replacement policies keep track of more usage information in order to improve the hit rate (for a given cache size).
The "latency" of a cache describes how long after requesting a desired item the cache can return that item (when there is a hit). Faster replacement strategies typically keep track of less usage information—or, in the case of direct-mapped cache, no information—to reduce the amount of time required to update that information.
Each replacement strategy is a compromise between hit rate and latency.
Measurements of "the hit ratio" are typically performed on benchmark applications. The actual hit ratio varies widely from one application to another. In particular, video and audio streaming applications often have a hit ratio close to zero, because each bit of data in the stream is read once for the first time (a compulsory miss), used, and then never read or written again. Even worse, many cache algorithms (in particular, LRU) allow this streaming data fill the cache, pushing out of the cache information that will be used again soon (cache pollution). [2]
Examples
Bélády's Algorithm
The most efficient caching algorithm would be to always discard the information that will not be needed for the longest time in the future. This optimal result is referred to as Bélády's optimal algorithm or the clairvoyant algorithm. Since it is generally impossible to predict how far in the future information will be needed, this is generally not implementable in practice. The practical minimum can be calculated only after experimentation, and one can compare the effectiveness of the actually chosen cache algorithm.
Least Recently Used
Least Recently Used (LRU): discards the least recently used items first. This algorithm requires keeping track of what was used when, which is expensive if one wants to make sure the algorithm always discards the least recently used item. General implementations of this technique require keeping "age bits" for cache-lines and track the "Least Recently Used" cache-line based on age-bits. In such an implementation, every time a cache-line is used, the age of all other cache-lines changes. LRU is actually a family of caching algorithms with members including: 2Q by Theodore Johnson and Dennis Shasha and LRU/K by Pat O'Neil, Betty O'Neil and Gerhard Weikum.
Most Recently Used
Most Recently Used (MRU): discards, in contrast to LRU, the most recently used items first. In findings presented at the 11th VLDB conference, Chou and Dewitt noted that "When a file is being repeatedly scanned in a [Looping Sequential] reference pattern, MRU is the best replacement algorithm."[3] Subsequently other researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (sometimes known as cyclic access patterns) MRU cache algorithms have more hits than LRU due to their tendency to retain older data.[4] MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed.
Pseudo-LRU
Pseudo-LRU (PLRU): For caches with large associativity (generally >4 ways), the implementation cost of LRU becomes prohibitive. If a scheme that almost always discards one of the least recently used items is sufficient, the PLRU algorithm can be used which only needs one bit per cache item to work.
Random Replacement
Random Replacement (RR): randomly select a candidate item and discard it to make space when necessary. This algorithm does not require keeping any information about the access history. For its simplicity, it has been used in ARM processors.[5] It admits efficient stochastic simulation.[6]
Segmented LRU
Segmented LRU (SLRU): An SLRU cache is divided into two segments. a probationary segment and a protected segment. Lines in each segment are ordered from the most to the least recently accessed. Data from misses is added to the cache at the most recently accessed end of the probationary segment. Hits are removed from wherever they currently reside and added to the most recently accessed end of the protected segment. Lines in the protected segment have thus been accessed at least twice. The protected segment is finite. so migration of a line from the probationary segment to the protected segment may force the migration of the LRU line in the protected segment to the most recently used (MRU) end of the probationary segment, giving this line another chance to be accessed before being replaced. The size limit on the protected segment is an SLRU parameter that varies according to the I/O workload patterns. Whenever data must be discarded from the cache, lines are obtained from the LRU end of the probationary segment.[7]"
2-Way Set Associative
2-way set associative: for high-speed CPU caches where even PLRU is too slow. The address of a new item is used to calculate one of two possible locations in the cache where it is allowed to go. The LRU of the two is discarded. This requires one bit per pair of cache lines, to indicate which of the two was the least recently used.
Direct-mapped cache
Direct-mapped cache: for the highest-speed CPU caches where even 2-way set associative caches are too slow. The address of the new item is used to calculate the one location in the cache where it is allowed to go. Whatever was there before is discarded.
Least-Frequently Used
Least Frequently Used (LFU): LFU counts how often an item is needed. Those that are used least often are discarded first.
Adaptive Replacement Cache
Adaptive Replacement Cache (ARC):[8] constantly balances between LRU and LFU, to improve combined result. ARC improves on SLRU by using information about recently-evicted cache items to dynamically adjust the size of the protected segment and the probationary segment to make the best use of the available cache space.
Clock with Adaptive Replacement
Clock with Adaptive Replacement (CAR) combines Adaptive Replacement Cache (ARC) and CLOCK. CAR has performance comparable to ARC, and substantially outperforms both LRU and CLOCK. Like ARC, CAR is self-tuning and requires no user-specified magic parameters.
Multi Queue Caching Algorithm
Multi Queue (MQ) caching algorithm:[9] (by Zhou, Philbin, and Li).
Other things to consider:
- Items with different cost: keep items that are expensive to obtain, e.g. those that take a long time to get.
- Items taking up more cache: If items have different sizes, the cache may want to discard a large item to store several smaller ones.
- Items that expire with time: Some caches keep information that expires (e.g. a news cache, a DNS cache, or a web browser cache). The computer may discard items because they are expired. Depending on the size of the cache no further caching algorithm to discard items may be necessary.
Various algorithms also exist to maintain cache coherency. This applies only to situation where multiple independent caches are used for the same data (for example multiple database servers updating the single shared data file).
See also
References
- ^ a b Alan Jay Smith. "Design of CPU Cache Memories". Proc. IEEE TENCON, 1987. [1]
- ^ Paul V. Bolotoff. "Functional Principles of Cache Memory". 2007.
- ^ Hong-Tai Chou and David J. Dewitt. An Evaluation of Buffer Management Strategies for Relational Database Systems. VLDB, 1985.
- ^ Shaul Dar, Michael J. Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan. Semantic Data Caching and Replacement. VLDB, 1996.
- ^ ARM Cortex-R series processors manual
- ^ An Efficient Simulation Algorithm for Cache of Random Replacement Policy [2]
- ^ Ramakrishna Karedla, J. Spencer Love, and Bradley G. Wherry. Caching Strategies to Improve Disk System Performance. In Computer, 1994.
- ^ Nimrod Megiddo and Dharmendra S. Modha. ARC: A Self-Tuning, Low Overhead Replacement Cache. FAST, 2003.
- ^ Yuanyuan Zhou, James Philbin, and Kai Li. The Multi-Queue Replacement Algorithm for Second Level Buffer Caches. USENIX, 2002.